
搜索结果: 1-10 共查到“文本数据”相关记录10条 . 查询时间(0.155 秒)
中国科学院计算机网络信息中心专利:一种高效的文本数据挖掘方法
中国科学院计算机网络信息中心 专利 文本数据 挖掘方法
2023/8/24
本发明公开了一种高效的文本数据挖掘方法,属于信息技术领域。本方法为:1)文件预处理阶段将内容经分词后的原文件合并为若干新文件;2)数据映射阶段计算每一词语在新文件中的总频数、在其中每一原文件中的频数及相对频率pr等,并将结果发送到重定向模块中;3)重定向阶段计算每一Reduce任务的负载量payload,并为每一Reduce任务设置一负载指示器payi;4)判断当前词语是否已分配了Reduce任务...

2023年4月26日上午,“南开旅游大讲堂(第188期)――杰出教授论坛”在学院111多功能厅顺利举行。应南开大学旅游与服务学院邀请,中国科学院大学经济与管理学院常务副院长李建平教授为南开大学旅游与服务学院师生带来了“基于多源文本数据的动态旅游风险感知――兼谈大数据管理决策”的精彩讲座。南开大学旅游与服务学院院长、教授、青年教师、博士后和硕博研究生等共计50余人参加了此次讲座,李辉教授担任此次讲座...
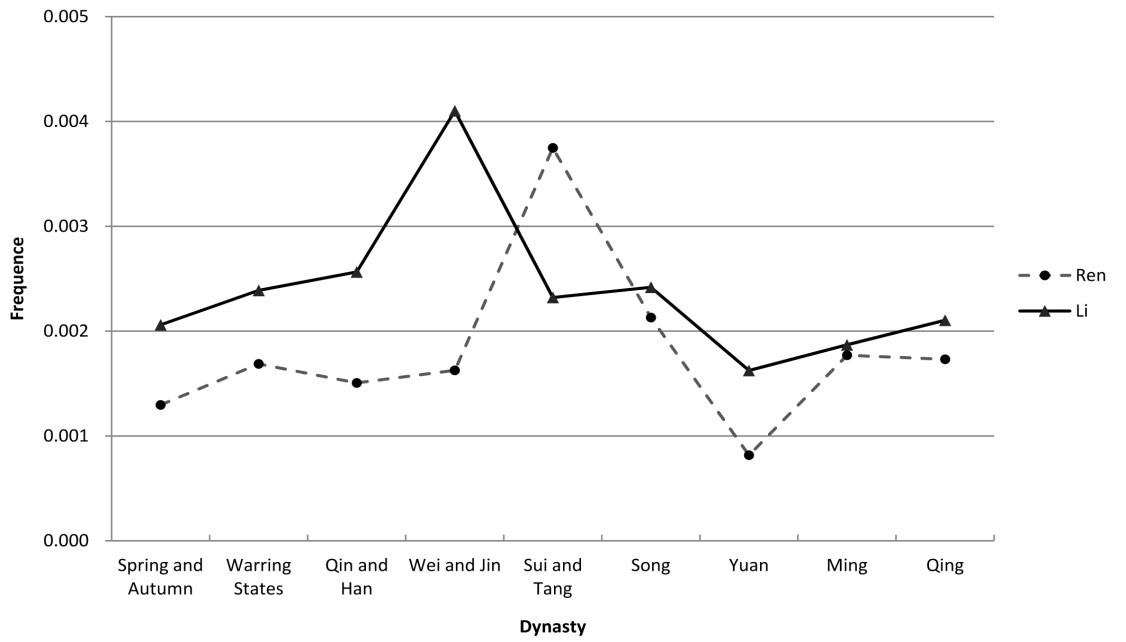
中国诸子百家文化中,以儒家文化最为光耀。自孔子创立以来,儒学居于中国思想文化主流2000余年,对中国民族文化心理结构影响深远。“仁”和“礼”是传统儒学之核心,也是中国传统道德文化核心价值的重要组成部分。一般认为,“仁”是内在的道德情感,“礼”是外在的行为规范;“仁”是“礼”的心理基础,“礼”是“仁”的体现、落实。以往研究大多集中于对“仁”“礼”词义的阐释、内在交互关系的分析、社会功能属性的探讨及重...
网络时代的心理与行为研究前沿――行为与文本数据分析研讨会邀请函
心理 行为与文本数据分析 研讨会
2015/9/1
互联网给人类生活带来了变革性的影响,对网络心理和行为的研究也日益成为研究者密切关注的重要研究主题。为了进一步推进国内网络心理与行为的深入研究和广泛运用,青少年网络心理与行为教育部重点实验室(华中师范大学)自2013年起主办“网络时代的心理与行为研究前沿”系列研讨会,旨在为网络心理学与计算行为科学的研究人员提供一个展示研究成果、交流学术思想、探索研究方向、推动研究发展的深入交流平台。
2014年11月20日上午,由中国科学院软件研究所青年联合会与天基综合信息系统重点实验室联合承办的数据挖掘技术交流研讨会在5号楼四层中会议室举行。活动邀请了中国科学院自动化研究所刘康博士做了题为“面向网络评论文本的观点信息抽取”的报告,来自软件所多个部门的青年科研人员和研究生约40人参加了此次活动。研讨会由天基综合信息系统重点实验室的王浩副研究员主持。
基于专利文本数据的技术实力评价方法
专利分析 专利评价 评价指标
2014/3/3
提出不依靠专利引文数据、利用专利文本数据评价企业技术实力的方法。【方法】该方法综合采用专利授权数量指标、专利增长率指标、技术中心性指标和专利最小价值指标来评估技术实力。这4类指标分别从技术规模、技术增长性、技术重要性和技术价值性等不同侧面反映一个企业的技术能力。【结果】通过CII和TII指标对比实验,验证引文分析给公开早的专利较高评价的问题;通过TS指标和TSQGIV对比实验,验证提出的技术实力评...
基于Squeezer 算法的文本数据流聚类
文本数据流 Squeezer算法 投影聚类
2014/10/8
为解决数据流聚类中的“链式数据”问题以及文本数据流存在的高维、稀疏、多主题问题, 以Squeezer 聚类算法为基础, 重新定义了聚类过程中类的质心、半径和判别距离. 提出了一种改进算法, 通过加入数据预处理环节来提高聚类精度, 通过投影聚类提高聚类效率并为簇赋予语义. 最后通过在互联网新闻语料的聚类实验, 表明了所提出的算法能够以较小的速度代价换来聚类效果的大幅提升, 性能显著优于Squeeze...
大规模文本数据库中的短文分类方法
文本挖掘 分类 短文 大规模文本数据库
2008/3/6
摘要信息技术的飞速发展造成了大量的文本数据累积,其中很大一部分是短文本数据。文本分类技术对于从这些海量短文中自动获取知识具有重要意义。但是由于短文中的关键词出现次数少,而且带标签的训练样本又通常数量很少,现有的一般文本挖掘算法很难得到可接受的准确度。一些基于语义的分类方法获得了较好的准确度但又由于其低效性而无法适用于海量数据。文本提出了一个新颖的短文分类算法。该算法基于文本语义特征图,并使用类似k...
利用关联规则对医学文本数据库进行知识抽取的尝试――以四种抗肿瘤药为例
知识抽取 关联规则 主题词 语义关系
2007/12/27
[摘要]利用关联规则算法,对PubMed数据库中的4种抗肿瘤药物主题词和副主题词组配模式进行分析,并以文献和教科书标准,抽取出与这四类药有关的、有效的语义关系搭配模式,从而为文献检索和建立知识库提供依据。