
搜索结果: 1-15 共查到“计算机科学技术 强化学习”相关记录36条 . 查询时间(0.756 秒)

CAA会士面对面系列活动是中国自动化学会为学会会士量身打造的高端学术交流平台,每期活动邀请1位或数位学会会士进行专题报告,围绕国际科技热点,聚焦国家创新发展战略需求,前瞻学科领域发展新方向,积极发挥学术引领和科技智库作用,展现重大学术咨询研究成果,引导社会尊崇科学思想和方法,促进公众提升科学意识和素养。
异策略深度强化学习中的经验回放研究综述
深度强化学习 异策略 经验回放 人工智能
2024/1/16
作为一种不需要事先获得训练数据的机器学习方法,强化学习(Reinforcement learning,RL)在智能体与环境的不断交互过程中寻找最优策略,是解决序贯决策问题的一种重要方法.通过与深度学习(Deep learning,DL)结合,深度强化学习(Deep reinforcement learning,DRL)同时具备了强大的感知和决策能力,被广泛应用于多个领域来解决复杂的决策问题.异策略...
强化学习(Reinforcement learning,RL)在围棋、视频游戏、导航、推荐系统等领域均取得了巨大成功.然而,许多强化学习算法仍然无法直接移植到真实物理环境中.这是因为在模拟场景下智能体能以不断试错的方式与环境进行交互,从而学习最优策略.但考虑到安全因素,很多现实世界的应用则要求限制智能体的随机探索行为.因此,安全问题成为强化学习从模拟到现实的一个重要挑战.近年来,许多研究致力于开发...
深度强化学习联合回归目标定位
视觉注意机制 循环神经网络 深度强化学习 目标定位
2024/1/17
为了模拟人眼的视觉注意机制,快速、高效地搜索和定位图像目标,提出了一种基于循环神经网络(Recurrent neural network,RNN)的联合回归深度强化学习目标定位模型.该模型将历史观测信息与当前时刻的观测信息融合,并做出综合分析,以训练智能体快速定位目标,并联合回归器对智能体所定位的目标包围框进行精细调整.实验结果表明,该模型能够在少数时间步内快速、准确地定位目标。
中国科学院声学研究所专利:强化学习推荐系统及方法一种用于广域网络的深度
运行指标决策问题是实现工业过程运行安全和生产指标优化的关键.考虑到多运行指标决策问题求解的复杂性和工业过程生产条件动态波动引发生产指标状态的不确定性,提出了一种策略异步更新强化学习算法自学习决策运行指标,并给出算法收敛性的理论证明.该算法在随机自适应动态规划框架下,利用样本均值代替计算生产指标状态转移概率矩阵,因此无需要求生产指标状态转移概率矩阵已知.并且通过引入时钟和定义其阈值,采用集中式策略评...
近年来,进化策略由于其无梯度优化和高并行化效率等优点,在深度强化学习领域得到了广泛的应用.然而,传统基于进化策略的深度强化学习方法存在着学习速度慢、容易收敛到局部最优和鲁棒性较弱等问题.为此,提出了一种基于自适应噪声的最大熵进化强化学习方法.首先,引入了一种进化策略的改进办法,在“优胜”的基础上加强了“劣汰”,从而提高进化强化学习的收敛速度;其次,在目标函数中引入了策略最大熵正则项,来保证策略的随...
深度强化学习方法取得了人工智能领域一个个里程碑式的成果,如视频游戏、围棋、国际象棋等完全信息博弈,麻将和星际争霸等更复杂场景下的不完全信息博弈,带动了广泛基础学科的发展和纵深应用领域的技术进步。然而,现实世界的更多问题是面向多任务的多智能体的机器博弈,是人工智能领域的下一项重大挑战。
组合优化问题广泛存在于国防、交通、工业、生活等各个领域,几十年来,传统运筹优化方法是解决组合优化问题的主要手段,但随着实际应用中问题规模的不断扩大、求解实时性的要求越来越高,传统运筹优化算法面临着很大的计算压力,很难实现组合优化问题的在线求解.近年来随着深度学习技术的迅猛发展,深度强化学习在围棋、机器人等领域的瞩目成果显示了其强大的学习能力与序贯决策能力。
复杂过程工业控制一直是控制应用领域研究的前沿问题.浓密机作为一种复杂大型工业设备广泛用于冶金、采矿等领域.由于其在运行过程中具有多变量、非线性、高时滞等特点,浓密机的底流浓度控制技术一直是学界、工业界的研究难点与热点.本文提出了一种基于强化学习技术的浓密机在线控制算法.该算法在传统启发式动态规划(Heuristic dynamic programming,HDP)算法的基础上,设计融合了评价网络与...
多机协同是空中作战的关键环节,如何处理多实体间复杂的协作关系、实现多机协同空战的智能决策是亟待解决的问题.为此,提出基于深度强化学习的多机协同空战决策流程框架(Deep-reinforcement-learning-based multi-aircraft cooperative air combat decision framework,DRL-MACACDF),并针对近端策略优化(Proxim...
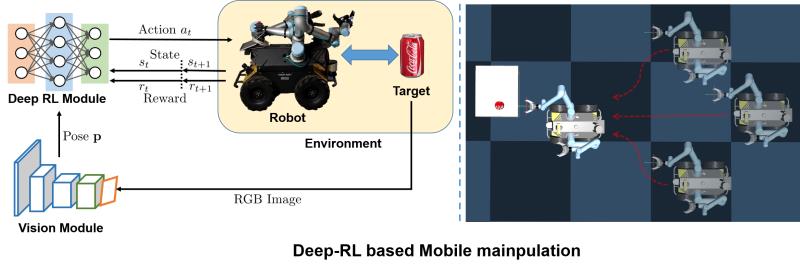
中国科学院沈阳自动化研究所与爱丁堡机器人中心在基于深度强化学习的机器人控制方面联合研究获进展(图)
中国科学院沈阳自动化研究所 爱丁堡机器人中心 深度强化学习 机器人控制 人工智能学习
2020/3/17
近日,中国科学院沈阳自动化研究所与英国爱丁堡机器人中心合作研究取得新进展,提出了一种在动态、非结构环境下基于深度强化学习的移动机械臂自主作业方法,将最新的人工智能学习理论成功应用于真实的复杂移动机械臂控制。相关研究成果发表于期刊Sensors。
中国自动化学会自适应动态规划与强化学习专业委员会
中国自动化学会 自适应动态规划 强化学习
2022/12/31
2016年与2017年,Deepmind团队开发的AlphaGo战胜了世界围棋冠军李世石与柯洁,掀起了人工智能的研究热潮,其中,AlphaGo使用的重要技术为深度强化学习。强化学习能在环境未知的情况下,通过决策者与环境的互动,实现优化决策,在计算机科学、自动化、运筹学等领域得到广泛研究。顺应人工智能的发展的大热潮,中国自动化学会自适应动态规划与强化学习专业委员会(Technical Committ...
Reinforcement Learning (RL) has achieved many successes over the years in training autonomous agents to perform simple tasks. However, it takes a long time to learn a solution and this solution can us...